
Von den Daten zur Geschichte: Ein typischer ddj-Workflow in R
Dieses Tutorial führt dich anhand eines einfachen Beispiels durch die Standardschritte des datenjournalistischen Workflows in der Programmiersprache R.

Für diesen Datenjournalismus R-Workflow schauen wir uns die Daten des BBSR an. Wie immer findest du die Daten und den gesamten Code auf unserer GitHub Seite. Diesmal ist das R-Skript als R-Projekt organisiert, was die Zusammenarbeit erleichtert, da das Arbeitsverzeichnis automatisch auf das Verzeichnis gesetzt wird, in dem sich die Rproj-Datei befindet. Ein Doppelklick auf die Rproj-Datei öffnet ein neues RStudio Fenster, das bereits auf das richtige Arbeitsverzeichnis der Analyse eingestellt ist. Dann kannst du das R-Skript wie gewohnt öffnen.
Hinweis: R hat eine große Auswahl an grundlegenden Funktionen, mit denen du eigentlich schon alles machen kannst. Da es Open Source ist, gibt es zusätzlich viele tolle Pakete mit weiteren Funktionen. Die folgenden fünf Pakete möchte ich dir ans Herz legen, wir werden sie auch in diesem Tutorial verwenden:
needs: needs ist eine hilfreiche Funktion, die das Installieren und Laden von Paketen so einfach wie möglich macht. Sobald du es installiert und geladen hast, wird needs dich fragen, ob es sich selbst laden darf, wenn es – naja – gebraucht wird. Sobald du ja zu dieser großartigen Funktion gesagt hast, brauchst du nie wieder ein Paket Schritt für Schritt zu installieren oder zu laden. Du musst nur alle benötigten Pakete in needs() auflisten, und es werden nur die Pakete installiert und/oder geladen, die noch nicht installiert und geladen sind.
# R
# Beispiel:
install.packages("needs")
library(needs)
needs(readxl, tidyr, dplyr, ggplot2)readxl: Ich weiß nicht, wie es dir geht, aber ich bekomme meine Daten meist in mehrseitigen Excel-Arbeitsblättern und konvertiere sie dann in CSV, weil Texteditoren und Programmiersprachen besser mit diesem Format arbeiten. Aber das Laden von CSVs in R kann eine echte Qual sein, wenn es um die chaotische Verwendung von Anführungszeichen, verschiedenen Trennzeichen oder Zeichen geht, die deutsche Umlaute, französische Apostrophe oder andere Eigenarten enthalten. Und ein Excel-Dokument mit mehreren Blättern in CSVs zu konvertieren ist ein Schritt mehr, als ich morgens machen möchte. readxl bietet die großartige Funktion read_excel(), die Daten aus Excel-Arbeitsblättern einfach laden kann.
# R
#example:
data <- read_excel("data.xlsx", sheet=4)
#oder
data <- read_excel("data.xlsx", sheet="sheet name")Ich mag meine Daten aufgeräumt und einfach zu handhaben. Die nächsten drei Pakete helfen dir, deine Daten aufzuräumen, sie (im positiven Sinne) zu manipulieren und deine Ergebnisse zu visualisieren.
tidyr: tidyr lässt deine Daten mit dem tidyverse verschmelzen, wie es der Schöpfer Hadley Wickham beschreibt: "Jede Variable ist eine Spalte, jede Beobachtung ist eine Zeile und jede Art von Beobachtungseinheit ist eine Tabelle. Dieses Framework macht es einfach, unordentliche Datensätze aufzuräumen, weil nur ein kleines Set von Werkzeugen benötigt wird, um mit einer großen Bandbreite von unordentlichen Datensätzen umzugehen."
Mit gather() kannst du deine Daten von einem breiten Format mit jeder Variable als Spalte in ein langes Format bringen, bei dem eine Spalte die Variablennamen und eine andere Spalte die passenden Werte enthält. Dieses Format mag schwieriger erscheinen, um sich manuell einen Überblick zu verschaffen, aber es funktioniert wie ein Zauber, wenn es mit den Funktionen aus den beiden folgenden Paketen verwendet wird.
dplyr: dplyr ist großartig, um Funktionen auf Teile deiner Daten anzuwenden. Es hilft dir, deine Daten zu filtern, zu gruppieren und zusammenzufassen. Einige der Funktionen werden wir später in diesem Beispielworkflow kennenlernen. Obwohl dplyr mit dem abhängigen Paket magrittr kommt, das wir brauchen, um die Funktionen zu verbinden, musst du manchmal magrittr zusätzlich installieren und laden, um sicherzustellen, dass alles funktioniert.
ggplot2: ggplot2 ist die Schönheit unter R’s Grafikpaketen. Ähnlich wie dplyr lässt ggplot2 dich seine Grafikfunktionen nacheinander verketten, was es super bequem macht, damit zu arbeiten. ggplot2 produziert großartige, qualitativ hochwertige Grafiken.
Ich unterteile meine R-Skripte immer grob in drei Teile:
Head: Der Teil, in dem ich Pakete und Daten lade
Processing: Der Teil, in dem ich die Daten bereinige und, nun ja, für die Analyse vorbereite
Analysis: Der Teil, in dem ich die Daten analysiere
Die drei Teile müssen nicht unbedingt im selben Skript stehen. Um die Analyse sauberer zu machen, könntest du den Head und die Vorverarbeitung in einer separaten R-Datei speichern, die entweder am Anfang des Analyseskripts gesourced werden kann oder die vorverarbeiteten Daten als neue Datenquelle speichert, die dann im Analyseskript geladen wird.
Head
Genug geredet! Beginnen wir mit dem Laden der Pakete, die wir für unsere Analyse benötigen.
# R
#install.packages("needs")
#library(needs)
needs(readxl,tidyr,dplyr,ggplot2,magrittr)Als nächstes müssen wir die Daten laden. Für dieses Beispiel habe ich ein Excel Worksheet mit zwei Datenblättern vorbereitet. Beide enthalten Daten zu Deutschlands 402 Kreisen und kreisfreien Städte. Wir haben die eindeutige Kreis-ID und den Kreisnamen sowie die Information, ob der Kreis ein Landkreis oder eine Stadt ist. Die erste Excel-Tabelle enthält das Durchschnittsalter der männlichen Bevölkerung des Kreises, die zweite enthält die gleichen Daten für die weibliche Bevölkerung.
Hinweis: Diese Statistik beruht auf der Fortschreibung der Zensusdaten aus Deutschland. Darin sind nur die Geschlechter "männlich" und "weiblich" erfasst.
# R
# Lade die beiden Datenblätter in zwei verschiedene Datenvariablen:
# Beispiel, wenn deine Daten in einer CSV vorliegen: file <- read.csv("file.csv", sep=",", dec=";", fileEncoding="latin1", na.strings="#")
age_male <- read_excel("age_data.xlsx", sheet=1)
age_female <- read_excel("age_data.xlsx", sheet=2)Processing
Nun, da wir die Daten haben, müssen wir ein wenig Preprocessing betreiben. Wir wollen beide Datensätze zu einem zusammenführen, der das Alter der männlichen und weiblichen Bevölkerung für jeden Bezirk enthält. Lass uns einen Blick auf die Datensätze werfen, um zu prüfen, ob wir die Zusammenführung durchführen können:
# R
head(age_male) # prüfe die ersten Zeilen der männlichen Altersdaten
head(age_female) # prüfe die ersten Zeilen der weiblichen Altersdaten
# prüfe die Anzahl der Zeilen
nrow(age_male)
nrow(age_female)Wir haben zwei Ergebnisse:
- Die Datensätze sind nicht gleich sortiert und die Spaltennamen sind auch nicht identisch. Glücklicherweise ist die Reihenfolge nicht wichtig für die Zusammenführung. Dazu kommen wir später.
- age_female hat mehr Zeilen als age_male und mehr Zeilen als es deutsche Kreise gibt. Was ist der Grund dafür?
Vielleicht gibt es doppelte Zeilen:
# R
any(duplicated(age_female)) # prüfe auf Duplikate in age_female
age_female <- unique(age_female) # Duplikate löschen
nrow(age_female) # rownumber erneut prüfenGut, wir mussten nur einige doppelte Zeilen entfernen. Jetzt lass uns die Datensätze zusammenführen!
Wenn sie genau gleich geordnet wären, könnten wir die Funktion cbind() verwenden, um einfach die Altersspalte von age_female zu age_male hinzuzufügen. Da aber die Reihenfolge nicht die gleiche ist, müssen wir merge() verwenden. merge() verbindet Datensätze nach einer Spalte mit eindeutigen Werten, die beide gemeinsam haben. Für unser Beispiel scheint die eindeutige Kreis-ID die beste Wahl zu sein. Da wir nur die Altersspalte von age_female hinzufügen wollen und nicht alle Spalten, wählen wir nur die erste und vierte Spalte aus, indem wir age_female[c(1,4)] indizieren. Dann müssen wir merge() den Namen der passenden Spalte mit den Parametern by.x für den ersten und by.y für den zweiten Datensatz mitteilen. Wenn die übereinstimmenden Spalten den gleichen Namen hätten, könnten wir nur den Parameter by verwenden.
# R
# Merging
age_data <- merge(age_male, age_female[c(1,4)], by.x="district_id", by.y="dist_id")
head(age_data) # sieht gut aus!P.S.: Das Merging funktioniert auch mit unterschiedlich langen Datensätzen. In diesem Fall kannst du angeben, ob du nicht übereinstimmende Zeilen behalten willst. Tippe ?merge in die R-Konsole für weitere Informationen.
Nun zur Aufräumarbeit: Wir wollen, dass die Spalten average_age_males und average_age_females in eine Spalte mit dem Variablennamen und eine mit den passenden Werten umgewandelt werden. Mit dem Parameter key sagen wir gather(), wie die neue Spalte mit den Attributnamen heißen soll. Mit value geben wir den neuen Spaltennamen für die Werte an und spezifizieren dann die Spalten, die durch Anwendung der Spalten-Indizes gesammelt werden sollen.
# R
# tidyverse
age_data <- gather(age_data, key=key, value=age, 4:5)
head(age_data) # das nenne ich tidy!Übrigens: 1:3 ist genau das gleiche wie c(1,2,3).
Analysis
Wie bereits erwähnt, ist dplyr ein sehr nettes Paket, mit dem du dir einen ersten Überblick über deine Daten verschaffen kannst. Wie tidyr ist es ein Paket von Hadley Wickham und wurde speziell für das tidy Datenformat entwickelt.
Hilfreiche dplyr Funktion, die wir in den folgenden Schritten verwenden werden
%>% und %<>%
Dies sind der magrittr pipe-Operator und der compound assignment pipe-Operator. Die Pipes verbinden Funktionen zu einer Kette von Funktionen. Jede Funktion arbeitet mit dem Ergebnis des vorherigen Kettengliedes. Die Zuweisungs-Pipe kann verwendet werden, um das Ergebnis der verketteten Funktionen direkt zuzuweisen.
# Beispiel: mean(x) ist dasselbe wie x %>% mean() und x %<>% mean() überschreibt die Variable x mit dem Ergebnis von mean(x)
summarize()
Die summarize Funktion fasst einen Datensatz anhand einer angegebenen Berechnung zusammen.
# Beispiel: Daten %>% summarize(result=sum(column1, column2))
group_by()
Die group_by Funktion kann verwendet werden, um eine Funktion auf verschiedene Gruppen des Datensatzes anzuwenden
# Beispiel: data %>% group_by(country) %>% summarize(sum=sum(city_income)) (der resultierende Datensatz wird einen Wert für jeden einzelnen Faktor in der Spalte "country" enthalten)
filter()
Diese Funktion filtert die Zeilen nach einer vorgegebenen Bedingung
# Beispiel: Daten %>% filter(Spalte1 %in% c(1,10))
mutate()
mutate fasst nicht den gesamten Datensatz zusammen, wie es summarize tut, sondern fügt das Ergebnis als neue Spalte hinzu
# Beispiel: data %>% group_by(country) %>% mutate(sum=sum(city_income)) (der resultierende Datensatz wird immer noch jede Zeile der ursprünglichen Daten enthalten)
arrange()
arrange sortiert den Datensatz in aufsteigender Reihenfolge nach einer Spalte. Für eine absteigende Reihenfolge verwende desc() innerhalb von arrange(). Du kannst mehr als eine Spalte angeben, nach der sortiert werden soll. Gleichstände in der ersten Spalte werden durch die nächste gebrochen und so weiter.
# Beispiel: Daten %>% arrange(desc(Spalte1), Spalte2) sortiert den Datensatz absteigend nach Spalte1 und dann aufsteigend nach Spalte2
select()
Wenn du nur bestimmte Spalten im resultierenden Datensatz beibehalten willst, verwende select, um sie auszuwählen oder zu entfernen
# Beispiel: data %>% select(1:3) oder data %>% select(c(1,4)) oder deselektierend: data %>% select(-5)
Lass uns einen Überblick über unsere Daten bekommen, indem wir die Werte filtern und zusammenfassen:
# R
# Fasse die Daten zusammen, um das Durchschnittsalter in Deutschland zu erhalten.
age_data %>% summarize(mean=mean(age))
# Gruppiere nun nach dem Spaltenschlüssel, um das Durchschnittsalter für Männer und Frauen in Deutschland zu erhalten
age_data %>% group_by(key) %>% summarize(mean=mean(age))
# Auf die gleiche Weise können wir auch nach anderen Spalten gruppieren, z.B:
age_data %>% group_by(city_county) %>% summarize(mean=mean(age))
# Berechne nun das Durchschnittsalter pro Kreis. Aber anstatt zusammenzufassen, speichere das Ergebnis in einer neuen Spalte.
# Diesmal speicherst du den neuen Datensatz als neue Variable in der R-Umgebung
age2 <- age_data %>% group_by(district_id) %>% mutate(district_mean=mean(age))
head(age2)
# Wir wollen nun die jüngsten Städte Deutschlands finden.
# Dafür brauchen wir die Spalten key und age nicht. Wir entfernen diese Spalten und reduzieren dann den Datensatz auf die eindeutigen Zeilen
age2 %<>% select(-c(4,5)) %>% unique()
head(age2)
# Benutze nun den Filter, um nur die Städte und nicht die Landkreise zu behalten und ordne den Datensatz in absteigender Reihenfolge nach dem district_mean
youngest_cities <- age2 %>% filter(city_county %in% "city") %>% arrange(district_mean)
head(youngest_cities)
# Als nächstes wollen wir uns nur die bayerischen Städte anschauen, deren Kreis-IDs alle mit "09" beginnen. Eine tolle Basisfunktion namens startsWith() kann leicht alle Kreis-IDs finden, die mit bestimmten Zeichen beginnen:
youngest_cities %>% filter(startsWith(district_id, "09"))
# Lass uns die älteste bayerische Stadt finden
youngest_cities %>% filter(startsWith(district_id, "09")) %>% arrange(desc(district_mean))Siehst du, wie dplyr es wirklich einfach macht, einen Blick auf verschiedene Aspekte deiner Daten zu werfen, indem du einfach verschiedene Funktionen kombinierst?
Du kannst sogar Fragen, die zunächst etwas schwieriger erscheinen, leicht beantworten, solange du deine R-Funktionen kennst. Das ist etwas, das mit Tools wie Excel nicht so einfach ist.
Zum Beispiel:
Lass uns die jüngste Stadt für jedes Bundesland finden.
Die Bundesländer haben eindeutige IDs, die durch die ersten beiden Zahlen der Kreis-ID repräsentiert werden. Also müssen wir die Daten nach den ersten beiden Zahlen der district_id gruppieren und dann nur die Zeile in jeder Gruppe auswählen, die den kleinsten Wert in district_mean hat. Um diese spezielle Gruppierung zu ermöglichen, brauchen wir die Hilfe der Basisfunktion substr(). Um zu überprüfen, wie sie funktioniert, gib einfach ?substr in deine Konsole ein.
Schließlich ordnest du die Daten in aufsteigender Reihenfolge nach dem district_mean an.
# R
youngest_cities %>% group_by(state=substr(district_id, 1, 2)) %>%
filter(district_mean %in% min(district_mean)) %>% arrange(district_mean)Nun nimm dir etwas Zeit, um dir vorzustellen, das gleiche Ergebnis mit einem Tool wie Excel zu erhalten…
Hast du verstanden, wie dplyr funktioniert? Dann probiere deine eigenen Kombinationen mit den Daten aus. Finde die Städte, die dem deutschen Altersdurchschnitt am nächsten kommen oder schaue, ob es mehr Kreise gibt, in denen Männer älter sind als Frauen oder ob es umgekehrt ist.
Visualisieren
Wir haben mittlerweile viel über unsere Daten herausgefunden, indem wir sie einfach gefiltert, zusammengefasst und geordnet haben. Aber manchmal hilft auch eine einfache Visualisierung sehr, um Muster zu finden.
Die folgende Anleitung ist nur eine mögliche Herangehensweise an eine Coropleth-Karte in R.
Zunächst benötigen wir einige Geodaten, die in verschiedenen Formaten, zum Beispiel als GeoJSON, bereitgestellt werden können. In diesem Beispiel haben wir ein ESRI Shapefile von Deutschlands Stadt- und Landkreisen. Ein ESRI Shapefile enthält mehrere Dateien, die im gleichen Verzeichnis gespeichert werden müssen. Nichtsdestotrotz werden wir nur die SHP-Datei mit rgdal’s readOGR() in R laden.
# R
needs(rgdal,broom)
krs_shape <- readOGR(dsn="krs_shape/krs_shape_germany.shp", layer="krs_shape_germany", stringsAsFactors=FALSE, encoding="utf-8")krs_shape besteht grundsätzlich aus zwei Teilen: Einem Datensatz in krs_shape@data und den geografischen Informationen in krs_shape@polygons. Der Datensatz hat eine Spalte KRS, die genau dieselben eindeutigen Kreis-IDs enthält wie unser Altersdatensatz. Wir könnten die Datensätze zusammenführen, das Shapefile plotten und den Plot entsprechend der Alterswerte einfärben.
Aber wie immer arbeite ich gerne mit aufgeräumten Daten. Deshalb haben wir vorher das Paket broom geladen. Wenn du einen Blick auf das Shapefile wirfst…
# R
head(krs_shape)
head(krs_shape@data)
head(krs_shape@polygons)…verstehst du vielleicht, warum ich die Daten ein wenig einfacher halten möchte. broom’s tidy()-Funktion vereinfacht die Geodaten:
# R
head(tidy(krs_shape))Viel besser! Wir haben hier eine Zeile pro Polygonpunkt und Gruppen-ID, so dass wir wissen, welche Punkte zur gleichen Form gehören.
Aber auch hier haben wir einen Informationsverlust: Wo ist die Kreis-ID?
Die Kreis-ID wird von broom weggefegt. Wir haben aber immer noch IDs, die bei Null beginnen und die Kreise in der gleichen Reihenfolge bezeichnen, wie sie in krs_shape@data auftauchen. Also hat "Schweinfurt" jetzt id=0 und "Würzburg" id=1.
Es mag einen einfacheren Weg geben, dieses Problem zu umgehen, aber hier ist, was ich normalerweise mache:
Im ersten Schritt speichere ich die Kreis-IDs des Shapefiles als numerische Werte in einer neuen Variable
# R
shape_district_ids <- as.numeric(krs_shape$KRS)Als nächstes ordne ich meinen Datensatz so an, dass er mit der Reihenfolge der IDs im Shapefile übereinstimmt und füge dann neue IDs von 0 bis 401 hinzu, die mit den aufgeräumten Shapefile-IDs übereinstimmen:
# R
age2 %<>% arrange(match(as.numeric(district_id), shape_district_ids))
age2$id <- 0:401Nun führe ich das aufgeräumte Shapefile mit meinen Daten anhand der neuen ID zusammen. Es ist wichtig, dass beim Mergen keine Shapefile-Zeilen verloren gehen und die Plot-Reihenfolge stimmt, also setze all.x auf TRUE und ordne in aufsteigender Reihenfolge nach der ID-Spalte.
# R
plot_data <- merge(tidy(krs_shape), age2, by="id", all.x=T) %>% arrange(id)
head(plot_data)Dies sind unsere endgültigen Plotdaten. Jeder Punkt des Shapefiles eines jeden Kreises hat nun zusätzliche Informationen wie das Durchschnittsalter des Distriktes. Lass uns diese Daten mit ggplot2 plotten!
Da wir bereits in einem vorherigen Beitrag erklärt haben, wie ggplot grundsätzlich funktioniert, werde ich nur den Code für das Choropleth kommentieren:
# R
cols <- c("#e5f5e0", "#c7e9c0", "#a1d99b", "#74c476", "#41ab5d", "#238b45", "#006d2c", "#00441b") # individuelles Farbschema setzen
ggplot(data=plot_data, aes(x=long, y=lat, group=group)) + # vergiss nie die Gruppierungsästhetik!
geom_polygon(aes(fill=district_mean)) +
theme_void() + # sauberes Hintergrundtheme
ggtitle("Durchschnittsalter der Landkreise in Deutschland") +
theme(plot.title = element_text(face="bold", size=12, hjust=0, color="#555555")) +
scale_fill_gradientn(colors=cols, space = "Lab", na.value = "#bdbdbd", name=" ") +
coord_map() # Projektion der Grafik ändernUnd so sollte das Ergebnis aussehen:
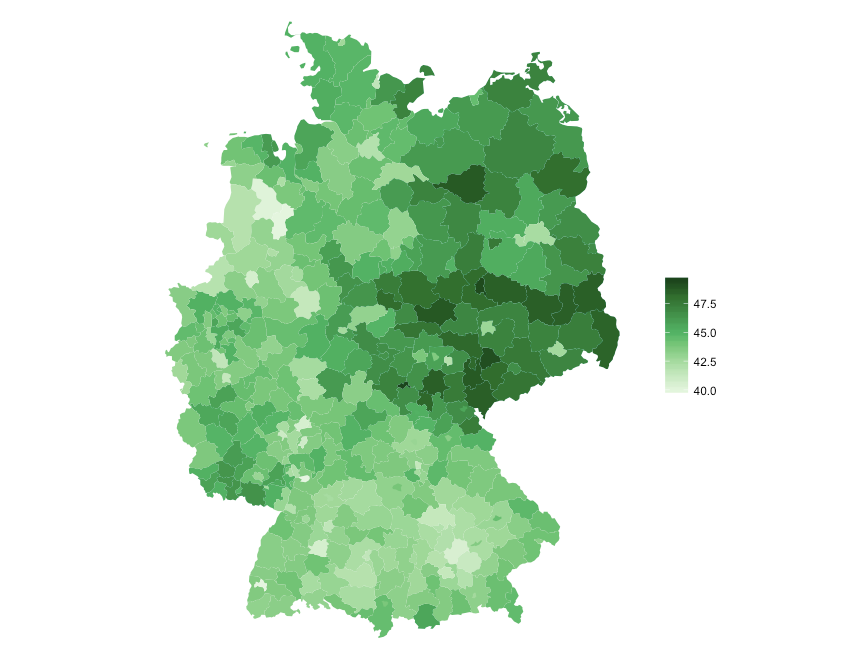
Natürlich sind unsere analysierten Beispieldaten kein Datengeschichtenschatz. Der alte Osten Deutschlands könnte eine Geschichte sein, eine unserer zusammengestellten Listen vielleicht auch. Oder die Ergebnisse geben dir nur einen Hinweis, wo du tiefer graben solltest. Welches Fazit du auch immer aus deiner kurzen Datenanalyse mit R ziehst: Es war kurz! Mit den wenigen R-Methoden, die wir dir heute gezeigt haben, wirst du nicht viel Zeit brauchen, um die ersten wichtigen Schlüsse aus den Daten zu ziehen. Und wenn das für den Anfang etwas viel für dich war, dann beschränke dich erstmal darauf, das einlesen und analysieren der Daten mit den dplyr-Werkzeugen zu üben! Denn Übung macht Meister*innen!
Wie immer findest du den gesamten Code für dieses Beispiel auf unserer GitHub Seite. Wenn du Fragen, Anregungen oder Feedback hast, kannst du gerne einen Kommentar hinterlassen!